Guía rápida de GIT
La Jaquería - 18 de marzo del 2024
¿Qué es GIT? ¿Para qué sirve?
Git es un sistema de control de versiones distribuído, sirve para:
- Tener una copia del trabajo en un servidor, de forma que si perdemos el portátil, no perdamos el trabajo realizado
- Llevar un registro histórico de los cambios realizados, pudiendo saber quién realizó cada cambio y cuándo.
- Permite trabajar a varias personas a la vez sobre los mismos archivos.
Nota: Aunque se puede usar con archivos binarios, Git está orientado a archivos de texto plano, siendo con éste tipo de archivos cómo se puede sacar el máximo partido a la herramienta.
1. Clonar el repositorio
El primer paso para trabajar con Git es hacer una copia local de los datos del servidor. Aunque es fácil instalar un servidor Git en cualquier máquina Linux, lo habitual es utilizar servidores en la nube como Github o Gitlab.
Entramos en github, buscamos el repositorio sobre el que queremos trabajar, y copiamos su url de clonado.
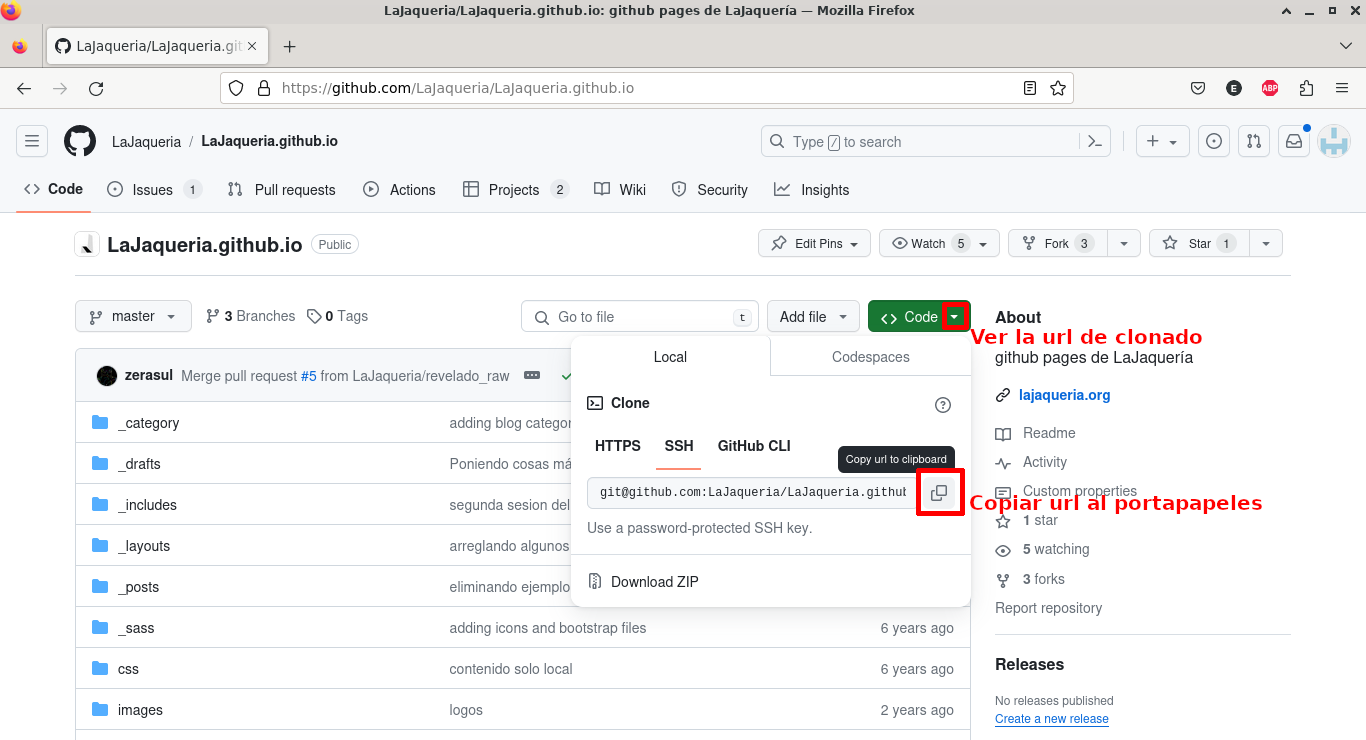
En nuestro ordenador, nos situamos en el directorio que queramos usar de trabajo y ejecutamos git clone [url]
Este comando puede tardar unos minutos, dependiendo del tamaño del repositorio y de la velocidad de nuestra conexión. Mientras se descarga, se muestra información del proceso
Una vez terminado el proceso de clonado, ya podemos trabajar con el repositorio
2. Crear una rama de trabajo
En git SIEMPRE SIEMPRE se trabaja sobre ramas. ¿Por qué? Porque trabajar con ramas es muy cómodo y útil, además Git está diseñado para que la manipulación de ramas sea muy ágil y rápida. Por esto sería absurdo no sacar provecho de la mayor virtud de Git.
Para crear una rama nueva, usamos git checkout -b [rama]
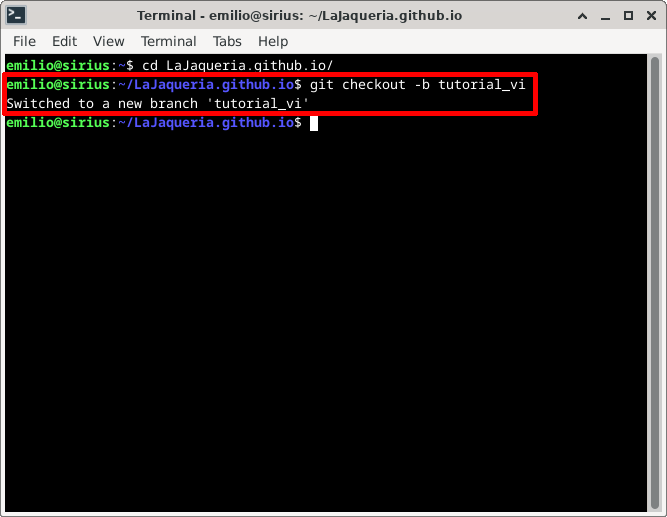
3. Listar los cambios pendientes de guardar
Cuándo hayamos alcanzado cualquier pequeño hito de avance en la tarea que tenemos entre manos, haremos un commit, de forma que si en sucesivos cambios la liamos, sea trivial volver a éste punto que consideramos bueno. Siempre que terminemos una jornada de trabajo, dejaremos la rama limpia, es decir subiremos todos los cambios realizados. Para comprobar que no tenemos nada pendiente, usamos git status
Ejecutamos git status para ver los cambios que hemos realizado
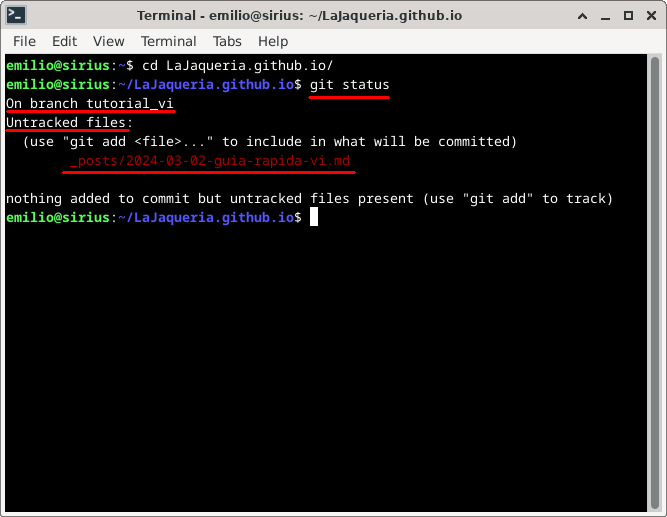
Lo primero de lo que nos informa este comando es de la rama en la que estamos * On branch tutorial_vi, en mi caso en tutorial_vi. A continuación nos muestra una lista de ficheros nuevos *Untracked files, en mi caso 2024-03-02-guia-rapida-vi.md
Si hubiese ficheros con cambios, éstos saldrían bajo el epígrafe Changes not staged for commit
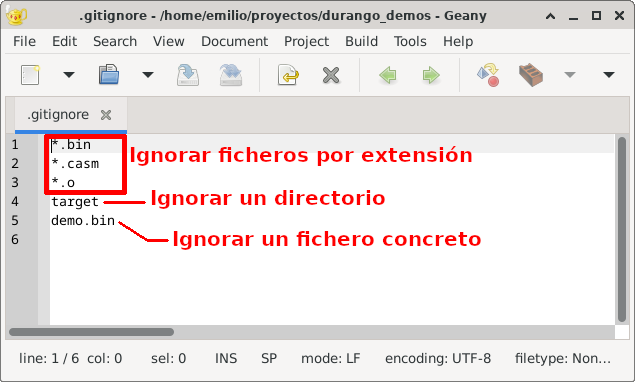
.gitignore
Es habitual que en el directorio de trabajo tengamos ficheros que no queremos guardar, por ejemplo binarios compilados, archivos temporales, etc. En git tenemos la opción de indicar que ficheros no se deben subir nunca, ésto se controla poniendo un fichero llamado .gitignore en la raíz del repositorio. Los ficheros indicados en .gitignore, dejarán de aparecer en git status
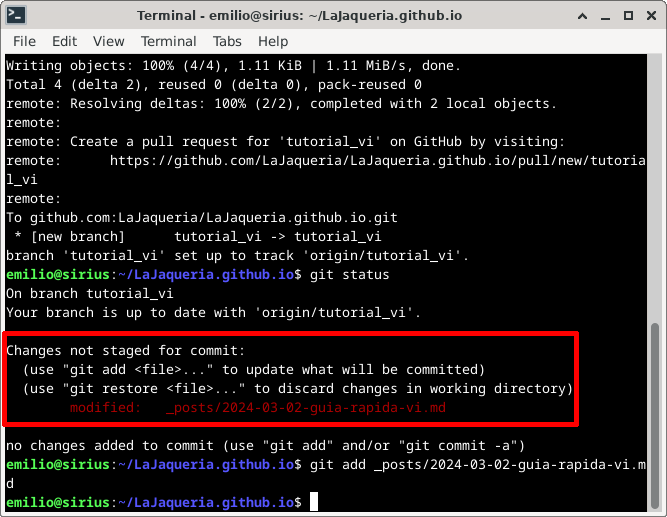
4. Guardar el trabajo
En git, el primer paso para subir cambios es marcar los ficheros que queremos subir como staged, en nuestro ejemplo, teníamos un único fichero, 2024-03-02-guia-rapida-vi.md (ver Captura 6). Para marcar el fichero, usamos git add [path]. Si queremos subir todos los ficheros anteriormente listados, podemos usar * como path. Una vez marcados, ejecutamos de nuevo git status para comprobar el listado de ficheros marcados, que aparecerá bajo el epígrafe Changes to be committed
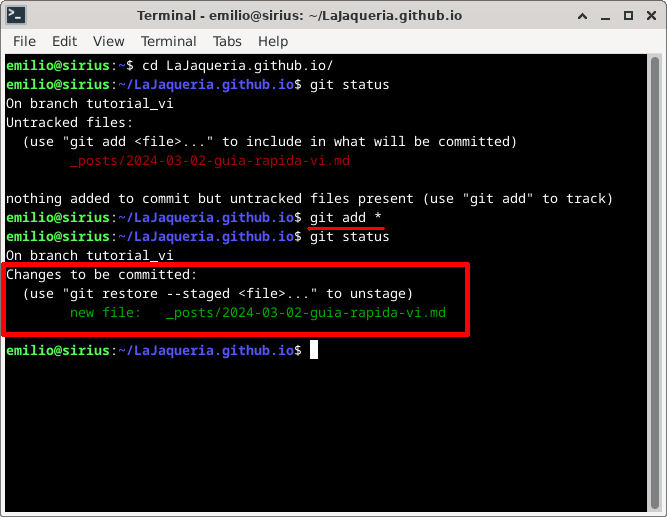
Una vez que tenemos marcados todos los cambios que queremos guardar, tenemos que ejecutar el comando git commit -m “descripcion de los cambios” para terminar de guardar los cambios realizados
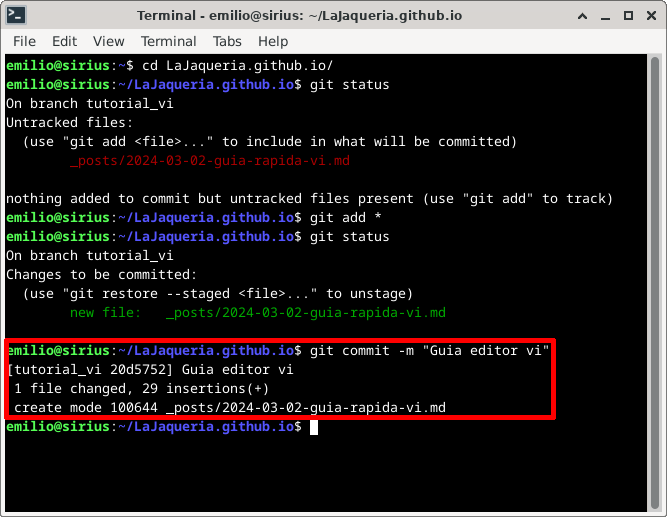
5. Subir los commits
Recordemos que Git es distribuído, eso significa que cuándo hacemos commit, sólo se está guardando en local ¡ojo! si se nos rompe el equipo, perderemos nuestro trabajo. Para subir los commits que hayamos hecho en nuestra rama ejecutamos git push. Si es la primera vez que subimos la rama, git nos dará un error indicando que no sabe con que rama remota conectar la rama local.
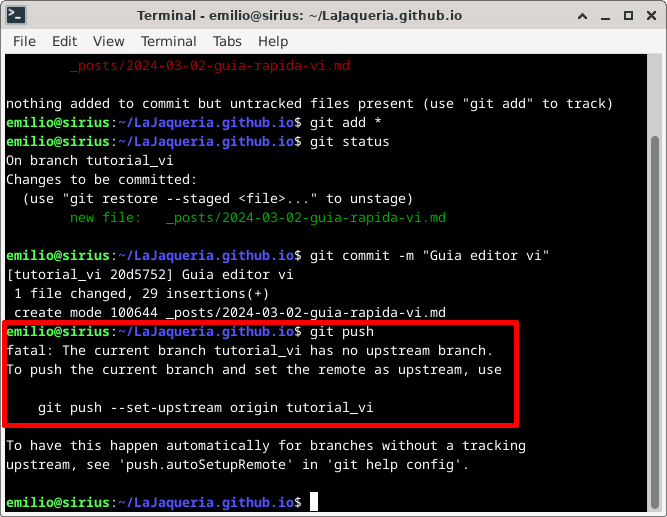
Para crear la rama en el servidor y conectarla con nuestra rama local, la primera vez ejecutaremos el comando git push -u origin [rama]
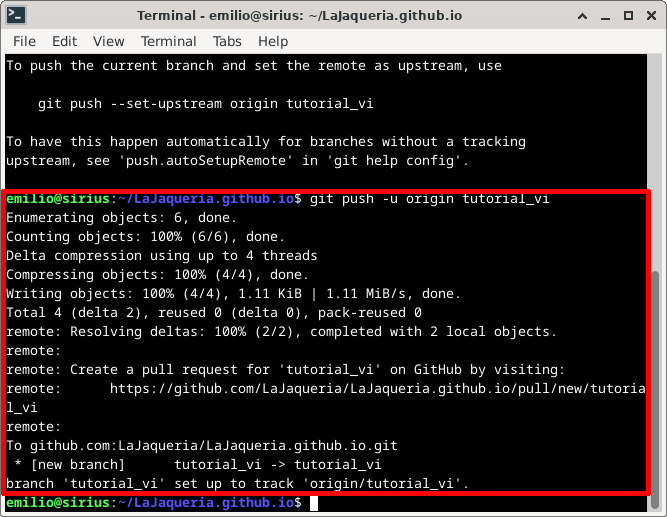
6. Integrar los cambios
Una vez demos por finalizado nuestro trabajo, tenemos que integrar nuestro cambio a master. Primero comprobamos que tenemos la rama limpia, es decir que no tenemos ningún cambio pendiente usando git status. Una vez realizada esta comprobación, pasamos a integrar los cambios de nuestra rama a master.
Cambiamos a la rama master con git checkout master y la actualizamos con git pull
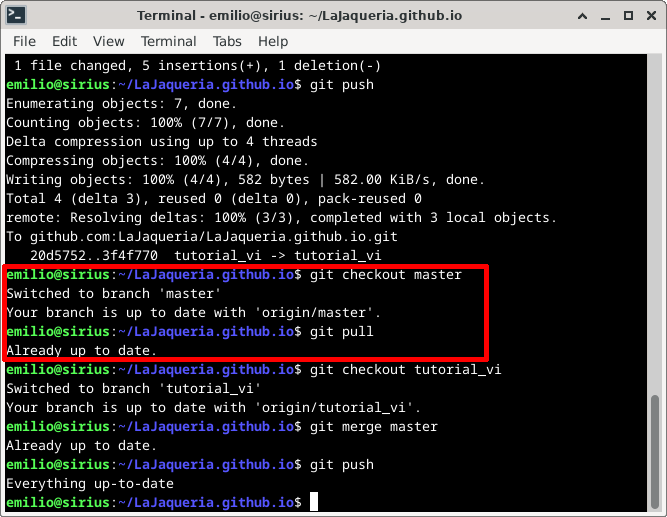
Volvemos a nuestra rama de trabajo con git checkout [rama] y realizamos la integración (merge) usando git merge master y la subimos con git push
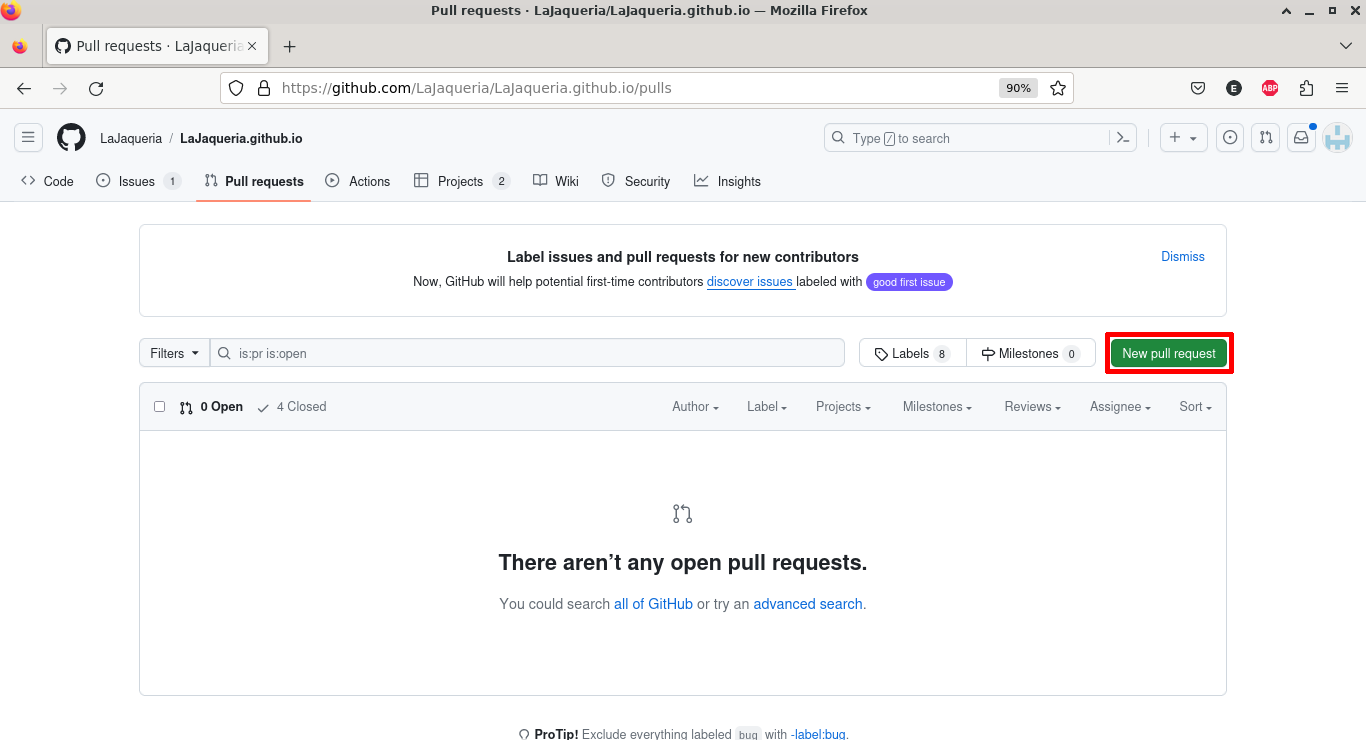
Una vez tenemos actualizada nuestra rama, abrimos PR para pedir la aprobación del resto del equipo, para ello vamos a la web de github (o gitlab) y navegamos a la pestaña Pull requests, y pulsamos el botón New pull request
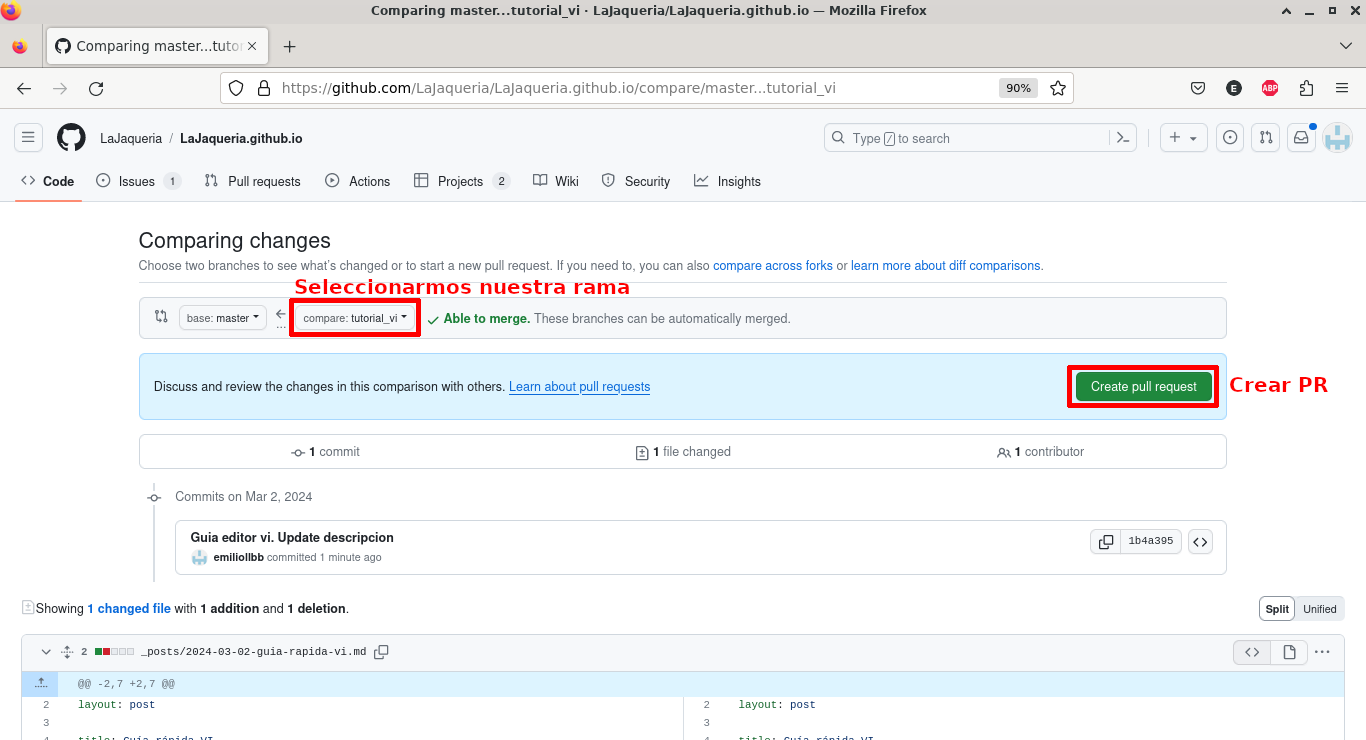
Seleccionarmos nuestra rama en el desplegable de origen, y pulsamos Create pull request
Escribimos un título y una descripción y pulsamos Create pull request
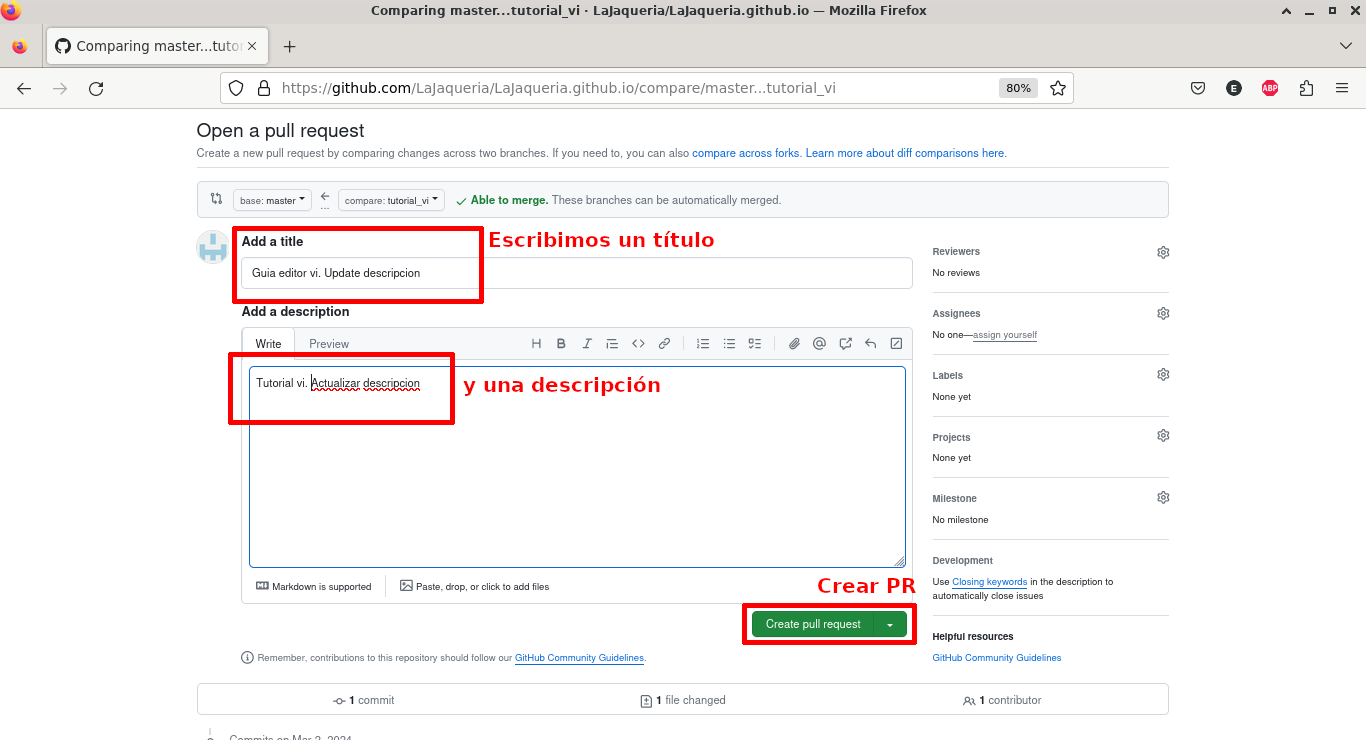
Cuando el responsable del repositorio realice la integración, el estado de la PR pasará a Merged
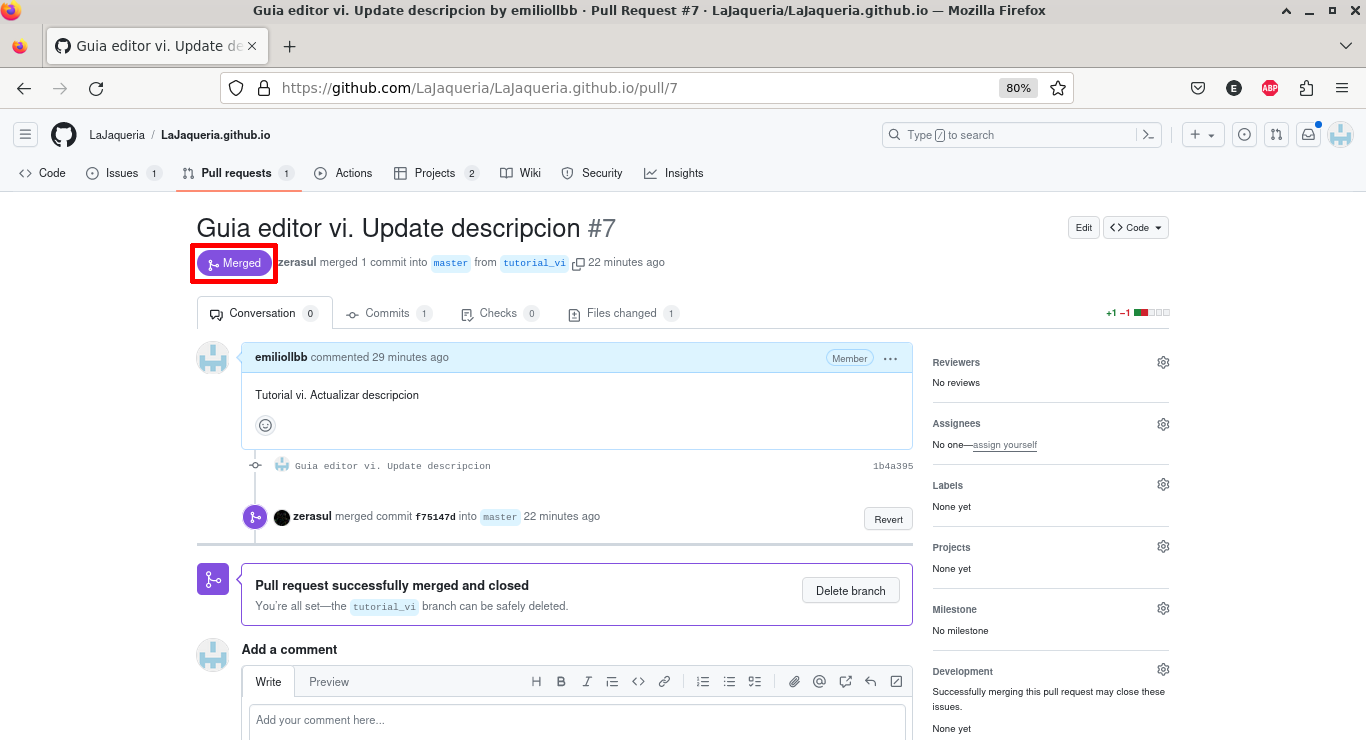
7. Resolución de conflictos
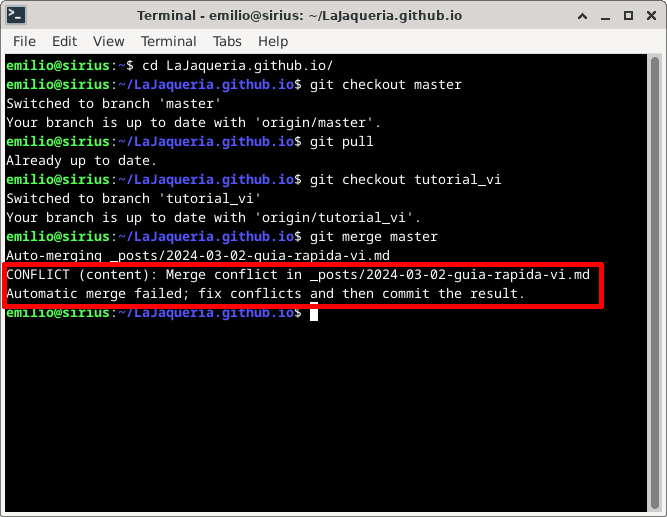
Al integrar los cambios de una rama a otra, es posible que aparezcan conflictos, ésto significa que la misma línea ha sido cambiada de dos formas distintas y git no sabe con cuál quedarse. Al realizar una integración con conflictos, git dará el error CONFLICT (content): Merge conflict in…
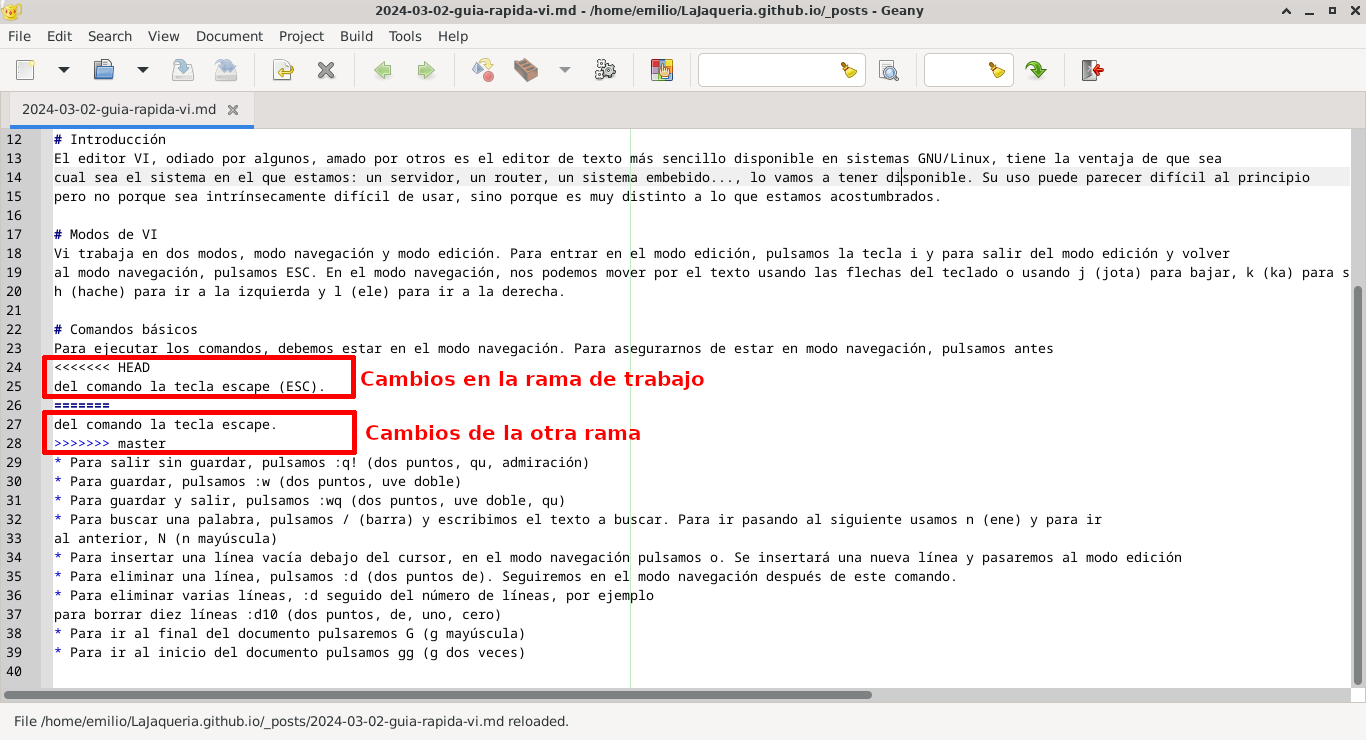
Tenemos que resolver los conflictos de cada uno de los archivos. Abrimos el fichero con conflictos y nos fijamos en los segmentos marcados con símbolos < < < < (menor) > > > > (mayor) y = = = = (igual). Estos símbolos indican los fragmentos en los que git no sabe que hacer, poniendo el contenido de ambas ramas separado por los iguales. Tenemos que editar el archivo eliminado las marcas y dejando el contenido adecuado según nuestro criterio.
8. Estrategias de integración
Para integrar el trabajo de una rama a otra en git, podemos usar dos estrategias distintas de integración, merge (la usada en los pasos anteriores) y rebase. La diferencia entre ambas es el orden de los commits, en la estrategia merge el orden de los commits se mantiene, de forma que se irán intercalando los trabajos de ambas ramas. En el caso de rebase, los commits de una rama se ponen a continuación de la otra, de forma que el trabajo de cada rama queda agrupado.